Phishing is a form of online identity theft associated with both social
engineering and technical subterfuge. As such, it has become a major
threat to information security and personal privacy. According to
Gartner Inc., in 2007, more than $3.2 billion was lost due to phishing
attacks in the US, and 3.6 million people lost money in such attacks. In
this article, we present an effective image-based anti-phishing scheme
based on discriminative keypoint features in webpages. We use an
invariant content descriptor, the Contrast Context Histogram (CCH), to
compute the similarity degree between suspicious pages and authentic
pages. The results show that the proposed scheme achieves high accuracy
and low error rates.
1 Introduction
Phishing is a form of online identity theft associated with both social
engineering and technical subterfuge. Specifically, phishers attempt to
trick Internet users into revealing sensitive or private information,
such as their bank account and credit card numbers. Unwary users are
often lured to browse counterfeit websites through spoofed emails, and
they may easily be convinced that fake pages with hijacked brand names
are authentic. When users unwittingly browse phishing pages, phishers
can plant crimeware, also known as malware, on the victims' computers.
Then, through the crimeware, phishers can steal users' private
information, redirect users to malicious sites directly, or redirect
them to the intended websites by way of phisher-controlled proxies.
The Anti-Phishing Working Group (APWG) reported that the number of
phishing webpages has increased by 28% each month since July 2004,
and 5% of users who receive phishing emails respond to such scams.
More than 66,000 cases of phishing were reported to, or detected by,
APWG in September 2007; and up to 95% of the phishing targets were
related to financial services and Internet retailers. According to a
survey by Gartner, Inc., in 2007, more than $3.2 billion was lost due
to phishing attacks in the United States, and 3.6 million people lost
money in such attacks. Phishing has thus become a serious threat to
information security and the privacy of Internet users.
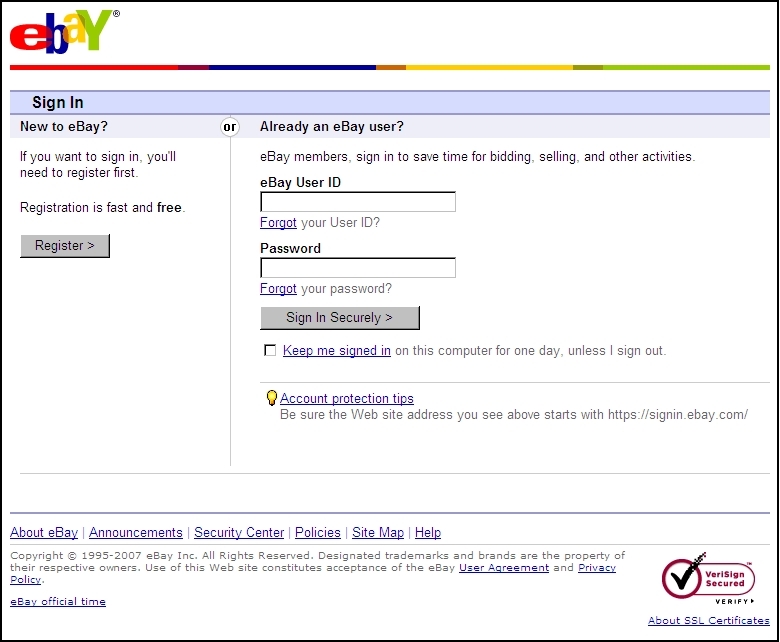
(a)
(b)
(c)
Figure 1: Comparison of the
official eBay page and phishing pages: (a) the official page; (b) a
phishing page with the modified logo; (c) a phishing page with an
advertisement banner inserted.
To deceive users into thinking phishing sites are legitimate, fake pages
are often designed to look almost the same as the official pages
in both layout and content. In addition, an arbitrary advertisement
banner may be inserted to redirect users to another malicious website if
they click on it. Take the phisher's favorite target, eBay, for example.
Figure 1(a) shows the login page of the official eBay
website, while Fig. 1(b) is a phishing page with a
slight modification to the logo; specifically, the logo is smaller and
the colored bar below the logo is missing. Figure 1(c)
is a phishing page with an advertisement banner placed at the top of the
page. These examples show how phishers ensnare the public and how
difficult it is for general users to distinguish between legitimate and
phishing pages.
2 Current Anti-phishing Techniques
Several anti-phishing techniques have been proposed in recent years to
strive to counter or prevent the increasing number of phishing attacks.
Generally speaking, phishing detection and prevention techniques can be
divided into two categories: 1) e-mail level approaches, including
authentication and content filtering; and 2) browser integrated tools,
which usually use URL blacklists, or employ webpage content analysis.
E-mail filtering techniques used to prevent phishing are quite popular
in anti-spam solutions, as both try to stop email scams from reaching
target users by analyzing the content of emails. The challenge in
designing such techniques lies in how to construct efficient filter
rules and simultaneously reduce the probability of false alarms.
Phishing messages are usually sent as spoofed emails; therefore, a
number of path-based verification methods have been proposed. Current
mechanisms, such as Sender ID proposed by Microsoft and DomainKey
developed by Yahoo, are designed by looking up mail sources in DNS
tables. However, these solutions have not been widely applied yet.
Currently, the companies only provide the mechanisms in their own
products and services free of charge.
A browser-integrated tool usually relies on a blacklist, which contains
the URLs of malicious sites, to determine whether a URL corresponds to a
phishing page or not. In Microsoft Internet Explorer 7, for example, the
address bar turns red when a malicious page is loaded.
The effectiveness of a blacklist is strongly influenced by its coverage,
credibility, and update frequency. At present, the most well-known
blacklists are those maintained by Google and Microsoft, which are used
by the most popular browsers, Mozilla Firefox and Microsoft Internet
Explorer, respectively. However,
experiments [10,4] show
that neither database can achieve a correct detection rate over 90%,
and the worst case scenario can be lower than 60%. Some
browser-integrated tools, e.g.,
SpoofGuard [2],
iTrustPage [11], and Liu et
al. [8,12]
adopt approaches other than blacklists. One of these approaches
examines the URL of a suspect page to determine if it is a spoofed
address. For example, http://fake.net/www.amazon.com/sign-in
may link to a phishing page that mimics
http://www.amazon.com/sign-in as the target. Some other
approaches focus on analyzing a webpage's content, such as the HTML
code, text, input fields, forms, links, and images.
In the past, the content-based approach, which analyzes the HTML code
and text on a webpage, proved effective in detecting phishing pages;
however, phishers responded by compiling phishing pages with non-HTML
components, such as images, Flash objects, and Java applets. For
example, a phisher may design a fake page which is composed entirely of
images, even if the original page only contains text information. In
this case, the suspect page becomes unanalyzable by content-based
anti-phishing tools as its HTML code contains nothing but HTML
<img/> elements. To address this problem, Fu et
al. [3] proposed detecting phishing pages
based on the similarity between the phishing and authentic pages at the
visual appearance level, instead of rather than using text-based
analysis. However, the proposed approach is susceptible to significant
changes in the webpage's aspect ratio and colors used.
3 The Proposed Scheme
As phishers may compose visually similar phishing pages in many
different ways with non-text HTML elements, such as images and Flash
objects, we compute the similarity of the phishing pages and the
authentic pages at their presentation level. Specifically,
we treat phishing page detection as an image matching problem.
Figure 2 illustrates the flow of our proposed detection
scheme, which involves two steps: 1) image-based page matching, and 2)
page classification.
Figure 2: The flow of the proposed phishing detection scheme. We first
take a snapshot of a suspect page, and extract its keypoint feature
information. Next, the features are matched with the keypoint feature
information of protected webpages. The suspect page can then be assessed
to determine whether or not it is a phishing page.
In the proposed scheme, we first take a snapshot of a suspect webpage
and treat it as an image in the remainder of the detection process. We
use the Contrast Context Histogram (CCH) descriptors proposed by Huang
et al. [6,7] to capture the
invariant information around discriminative keypoints on the suspect
page. The descriptors are then matched with those of the authentic
pages of the protected domains, which are stored in a database compiled
by users and authoritative organizations, such as the Anti-Phishing
Working Group (APWG). The matching of CCH descriptors yields a
similarity degree for a suspect page and an authentic page. Finally, we
use the similarity degree between two pages to determine whether the
suspect page is a counterfeit or not. If the similarity degree between
a phishing page and an authentic page is greater than a certain
threshold, the suspect page is considered as a phishing page of the
authentic page, and considered genuine if it is not a phishing page of
any of the authentic pages in the database.
3.1 Contrast Context Histogram (CCH)
Image matching techniques have long been used for a long time in the
computer vision and image processing fields. To determine whether two
images are similar, a common approach involves extracting a vector of
salient features from each image, and computing the distance between the
vectors, which is then taken as the degree of visual difference between
the two images.
The color histogram, which represents the distribution of the colors
used in an image, for example, is one of the most widely-used features
for image matching. However, we consider it unsuitable for computing
the similarity between webpages. The reason is that webpages usually
contain fewer colors than paintings; thus, it is not uncommon to find
that many webpages have similar color distributions. In other words, the
color histogram is not a useful discriminative feature for judging the
similarity of webpages.
We use the Contrast Context Histogram
(CCH) [6,7] descriptor
because of its effectiveness and computational efficiency.
Originally, the CCH descriptor was designed to achieve scale- and
rotation-invariance in image matching; that is, two images are
considered similar even if one of them has been undergone various types
of scale- or rotation-transformation. However, such transformations are
rarely seen in phishing pages because the pages must be very similar to
the corresponding authentic pages in order to deceive unsuspecting
users. Thus, we adapt the CCH descriptor to a more light-weight design
for webpage comparisons. We call our design the L-CCH descriptor
hereafter.
Figure 3: (Left) Keypoints (marked by green crosses) detected
in the image. Keypoints are the points in an image that can still be
detected easily after changes (e.g., lighting variations) are applied.
(Right) The log-polar coordinate system centered on a keypoint. The
angle coordinate is divided into 8 levels, and the distance coordinate
is divided into 3 levels; we have n=24 sub-regions as a
result.
To construct L-CCH descriptors for an image, we only use the gray-level
information, which we obtain by averaging the red, green, and blue
values of each pixel in the image. The Harris-Laplacian corners are then
taken as the keypoints of the image. Readers not familiar with the
Harris-Laplacian corner may refer to Mikolajczyk and Schmid's
work [9] for details. Basically, the
corner-detection method finds a number of salient points in an image. A
point is considered a keypoint if it can still be detected after the
image undergoes various changes, such as shifting, lighting variation,
color transformation, or format conversion. Fig. 3
shows an example of the keypoints detected (marked by the green crosses)
in an image.
(a)
(b)
Figure 4: The L-CCH descriptor with the
log-polar coordinate system. (a) The gray-value contrast value between
neighboring pixels and the keypoint (the center). (b) The L-CCH
descriptor with a 2-tuple contrast vector in each
sub-region.
We use the relative brightness of neighboring pixels to describe a
keypoint. By uniformly quantizing the azimuth angle and the distance
coordinates, the neighbor region of each keypoint is divided into n
non-overlapping sub-regions, where n=24 in
Fig. 4. The advantage of using a log-polar
coordinate system is that this system is more sensitive to the image
points nearby the center than those points farther away.
For each neighboring pixel of a keypoint, we calculate the contrast value,
i.e., the difference between the gray levels of the pixel and those of the
keypoint. As shown in Fig. 4(a), a sub-region may
contain some pixels with positive contrast values (the pink pixels), and
some with negative contrast values (the blue pixels). We summarize the
information in each sub-region by averaging the positive and negative
contrast values respectively; therefore each sub-region can be described by
a 2-tuple contrast vector, as shown in Fig. 4(b). We
then concatenate the contrast vectors of all sub-regions to form a
2n-dimensional vector and define it as the L-CCH descriptor, where n is
the number of sub-regions.
Finally, to make the L-CCH descriptor invariant to linear lighting changes,
we normalize it to a unit-length vector.
Having obtained the L-CCH descriptor for each keypoint, we can quantify
the similarity between two keypoints based on the Euclidean distance
between their descriptors. A short Euclidean distance indicates that
the keypoints are similar in terms of neighboring information. Based on
this property, we find the most similar keypoint on a suspect webpage
for each keypoint, K, on the authentic webpage by the following steps:
First, we search for the two keypoints, A and B, on the suspect page
that have the shortest and the second-shortest Euclidean distances from
the keypoint, K, on the authentic page. Second, we consider K and
A as a successful match if the ratio between the distance from K to
A and the distance from K to B is smaller than a certain threshold
(set to 0.6 in our experiments); otherwise, we consider that the
keypoint K has no corresponding keypoints on the suspect page. An
example of image correspondence found by the L-CCH descriptor is shown
in Fig. 5, where a line connecting two keypoints
means that a match exists between the images.
Figure 5: Sample result of image matching using the L-CCH
descriptor.
3.2 Page Similarity Degree
To determine whether a suspect webpage is a phishing webpage, we
evaluate its similarity to the potential target based on CCH
descriptors.
Ideally, the number of successful matches found by descriptors should
indicate the degree of similarity between the two pages. However, this
is not always true in the cases of webpage comparison. Two webpages may
have a number of keypoint matches not because they look similar, but
simply because they contain the same logo, e.g., the logo of VeriSign,
Inc., a well-known identity protection service provider. Therefore, to
judge the similarity of two webpages, we need to consider not only the
number, but also the spatial distribution, i.e., the
locations, of the matched keypoints.
Figure 6: Clustering and matching of eBay's official
page and a phishing page. Different clusters are circled in different
colors.
Figure 7: Matching two pages from different sites. In this
case, there are too few matched keypoints required to perform
clustering.
To take the location of matched keypoints into account, we use the
k-means algorithm [5] to divide them into
a number of coherent groups based on their spatial distributions. The
algorithm ensures that the keypoints in a group are always in a
neighboring region. Figure 6 shows the
clustering result of the official eBay webpage (left-hand side) and a
phishing eBay page (right-hand side), where k=4 groups are circled
using different colors. Based on the results, we match groups of
keypoints between the two webpages by voting; that is, for a group of
keypoints, A, on the authentic page, a group of keypoints, B, on the
suspect page will be considered as A's mapping if most of the
keypoints in A match keypoints in B. We then define a keypoint as
geographically matched if its group is a mapping of its
corresponding keypoint's group. In cases where two pages are dissimilar,
the number of matched points will be small so that the clustering cannot
even be performed. For example, Fig. 7
shows the matching result of pages from different sites. Although a few
of match, none of them are considered geographically matched as no
clusters are found. Given the geographical matching information, we
define the similarity degree between two webpages by the ratio of
geographically matched keypoints to all the identified keypoints on the
two pages. As phishing pages are similar to the authentic pages they try
to mimic, we use the similarity degree between a suspect webpage and the
authentic page to determine whether the suspect is indeed a counterfeit,
which is normally designed to steal users' sensitive information.
4 Performance Evaluation
Table 1: The Top 5 Phishing Target Sites
Sites
Number of Records
CR
FNR
FPR
eBay
701
96.8%
0.0%
0.1%
PayPal
632
97.7%
0.0%
0.1%
Marshall & Ilsley Bank
138
97.7%
0.0%
0.1%
Charter One Bank
116
98.0%
0.0%
0.1%
Bank of America
51
95.4%
2.0%
2.1%
Total Number of Phishing Target Pages: 300 pages in 74 sites.
According to a survey conducted by Secure
Computing [1], more than half the phishing attacks in
2007 were targeted famous websites, such as eBay, a popular online
auction service, and PayPal, a popular online billing service. For this
reason, we collected a number of real-life phishing webpages that
targeted the top 5 phishing targets, namely eBay, PayPal, Marshall and
Ilsley Bank, Charter One Bank, and Bank of America. In addition, we
collected 300 webpages of well-known online bank and auction services,
which are often targeted in phishing attacks in order to observe the
distribution of 1) the similarity degree between a phishing page and its
corresponding authentic page, and 2) the similarity between two
unrelated webpages. We find that the former is normally a small value
around zero, while the latter is normally a large value around one.
Based on our observations, we empirically set the threshold to 0.6 and
determine that a suspect page is a phishing page if its similarity
degree is higher than this threshold. The evaluation results listed in
Table 1 show that our scheme achieves a high degree of
accuracy that ranges between 95% and 98%; moreover, the error
rates, i.e., the false positive rate and false negative rate, are much
lower than 1% in most cases.
Case Studies
Figure 8: Case study: the login page and a phishing page of
Bank of America
In the following, we explain how our detection scheme works in real-life
cases. Although phishers endeavor to make phishing pages
indistinguishable from the authentic pages to deceive users, they
usually make some modifications to evade phishing detection techniques.
In our first case, which is a typical example, the phishers add an
advertisement banner to the phishing page to slightly alter the layout.
The change may not be noticed by unwary users, but it may make
anti-phishing tools less effective. Figure 8 shows
the authentic Bank of America login page on the left-hand side, and a
phishing page with an advertisement banner inserted on the right-hand
side. Because the change is minor and Internet users are accustomed to
advertisements on webpages, the inserted banner may go unnoticed by
users. Even so, the banner changes the aspect ratio of the page and
adds a great deal of red to the image, which will reduce the detection
ability of anti-phishing solutions based on color distributions and page
layout. In contrast, the effectiveness of our scheme is not degraded
because it is based on local discriminative keypoints, which are
invariant to changes in image layout and color distribution, the banner
insertion does not affect the effectiveness of our scheme. It is worth
noting that such banners not only help phishers evade anti-phishing
solutions, but also make money for the phishers every time a banner is
displayed on a user's computer.
Our second case demonstrates another common phishing strategy whereby
phishers alter the input form by adding or removing fields. For example,
in the Bank of American case shown in Fig. 8, the
phishers added an additional "Enter Passcode" field to the phishing
page. As a result, unwitting users may provide sensitive information
without realizing that such information is not requested on the
authentic page.
In other cases, phishers add fields that ask for more private data from
users, such as credit card numbers and social security numbers. It is
difficult for most users to detect that these modifications are fake
because people do not usually remember exactly what fields should appear
on an input form. Once again, this case demonstrates the efficacy of
our scheme. Even though both the advertisement banner and the
additional field alter the page layout and aspect ratio, our CCH
descriptor still yields a near perfect matching between the keypoints of
the phishing and authentic pages.
The above examples demonstrate how phishers can alter the design of an
authentic webpage to deceive unwary users. Nevertheless, to ensure that
phishing pages are similar to the authentic pages, most of the main
elements of the original page must to be preserved. Our scheme is
capable of detecting the similarity between fake pages and the original
pages regardless of the types of changes.
5 Conclusion
Phishing has become a major threat to information security and personal
privacy, and many people have been cheated out of vast sums of money as
a consequence. As phishing pages often look almost identical to their
target pages, many anti-phishing solutions, such as content analysis and
HTML code analysis, rely on this property to detect fake webpages.
However, phishers are now countering these detection techniques by
composing phishing pages with non-analyzable elements, such as images
and Flash objects, even though the pages still look like the authentic
pages. To address this problem, we propose an image-based phishing
detection scheme that uses the Contrast Context Histogram, a descriptor
for describing local-invariant discriminative keypoints. The results of
evaluations and case studies show that our scheme can detect phishing
pages with a high degree of accuracy and only a few false alarms.
Moreover, as our scheme is purely based on passive monitoring of web
pages that users browse, it is orthogonal to other solutions and
therefore can be freely integrated with existing prevention and
detection schemes to fight phishing together.
Acknowledgement
This work was supported in part by Taiwan Information Security Center
(TWISC), National Science Council under the grants NSC97-2219-E-001-001 and
NSC97-2219-E-011-006. It was also supported in part by Taiwan E-learning and
Digital Archives Programs (TELDAP) sponsored by the National Science Council
of Taiwan under the grants NSC98-2631-001-011 and NSC98-2631-001-013.
References
[1]
"Phishing statistics," Secure Computing, 2007,
http://www.ciphertrust.com/resources/statistics/phishing.php.[2]
N. Chou, R. Ledesma, Y. Teraguchi, and J. C. Mitchell, "Client-side defense
against web-based identity theft," in NDSS. The Internet Society, 2004.
[3]
A. Y. Fu, L. Wenyin, and X. Deng, "Detecting phishing web pages with visual
similarity assessment based on earth mover's distance (EMD)," IEEE
Trans. on Dependable and Secure Computing, vol. 3, no. 4, pp. 301-311,
2006.
[4]
B. M. Hämmerli and R. Sommer, Eds., Detection of Intrusions and
Malware, and Vulnerability Assessment, 4th International Conference, DIMVA
2007, Lucerne, Switzerland, July 12-13, 2007, Proceedings, ser. Lecture
Notes in Computer Science, vol. 4579.
Springer, 2007.
[5]
J. Han and M. Kamber, Data Mining: Concepts and Techniques (The Morgan
Kaufmann Series in Data Management Systems). Morgan Kaufmann, September 2000.
[6]
C.-R. Huang, C.-S. Chen, and P.-C. Chung, "Contrast context histogram - a
discriminating local descriptor for image matching," in ICPR
(4). IEEE Computer Society, 2006, pp.
53-56.
[7]
--, "Contrast context histogram-an efficient discriminating local
descriptor for object recognition and image matching," Pattern
Recognition, vol. 41, no. 10, pp. 3071-3077, 2008. [Online]. Available:
http://imp.iis.sinica.edu.tw/CCH/CCH.htm[8]
W. Liu, X. Deng, G. Huang, and A. Y. Fu, "An antiphishing strategy based on
visual similarity assessment," IEEE Internet Computing, vol. 10,
no. 2, pp. 58-65, 2006.
[9]
K. Mikolajczyk and C. Schmid, "Indexing based on scale invariant interest
points," in Proc. of the Int. Conf. on Computer Vision, vol. 1, 2001,
pp. 525-531.
[10]
P. Robichaux and D. L. Ganger, "Gone phishing: Evaluating anti-phishing tools
for windows," September 2006, http://www.3sharp.com/projects/antiphishing/.[11]
T. Ronda, S. Saroiu, and A. Wolman, "iTrustPage: A user-assisted
anti-phishing tool," the Proceedings of the ACM European Conference on
Computer Systems (EuroSys), April 2008.
[12]
L. Wenyin, G. Huang, L. Xiaoyue, Z. Min, and X. Deng, "Detection of phishing
webpages based on visual similarity," in WWW (Special interest tracks
and posters), A. Ellis and T. Hagino, Eds. ACM, 2005, pp. 1060-1061.
Sheng-Wei Chen (also known as Kuan-Ta Chen) http://www.iis.sinica.edu.tw/~swc
Last Update September 28, 2019
 (a)
(a)
 (b)
(b)
 (c)
(c)







