計畫成員 : 洪鼎詠、吳真貞
在2021年,吳博士和洪博士的研究團隊開始了一個為期三年的IIS合作計畫,其研究目標在提升深度學習軟體的執行效能。這個計畫的動機源自於近年來深度學習模型的快速發展,除了容量大幅增加,這些模型變得更深、更寬以及更複雜的神經網路架構,這些複雜深度學習軟體已廣泛地應用在各種智慧系統中,包括自駕車和語音助理等。雖然這些模型大幅提升了預測準確性,但也同時大幅增加了執行所需的時間。另一方面,現代計算機廣泛採用了異構系統架構(Heterogeneous System Architecture),將不同類型的運算裝置如CPU、GPU、FPGA和AI加速器等集成在一起,此異構系統架構為提升深度學習模型執行效能提供了充分的優化機會。針對此挑戰,研究團隊從編譯器優化和計算機架構角度切入此問題,開發了新的排程方法、平行計算技術和高效執行碼編譯。我們的研究成果發表在頂級期刊和國際會議並獲得了研究獎,並從2022年8月起,促成了資訊所、台達電子以及國立台灣大學的產學合作。
此研究計畫從三個方向優化深度學習模型的執行時間。(1)設計高效排程演算法安排深度模型計算和異構裝置的執行規劃、(2)計算資源使用率的最大化、(3)壓縮模型如剪枝和量化神經網絡的執行碼優化。
排程算法設計
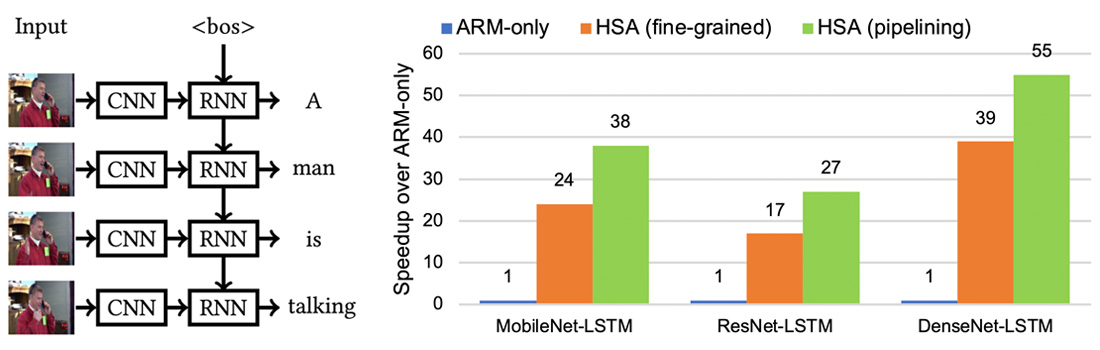
設計一個高效異構系統排程算法需要同時考慮下列四項因素。一、計算環境中包含不同類型運算裝置,因此我們需要將模型中各項計算分配給最佳的運算裝置執行。二、排程分配單位(granularity)會影響執行效能,例如一次分配一個模型(粗粒度)或一次分配一個運算子(細粒度)有非常不同的計算行為。三、排程規劃必須遵守模型運算子執行順序並避免運算裝置的競爭。四、降低因運算配置到不同運算裝置時所造成的資料傳輸負擔。針對這些因素,我們利用事先建立好的運算裝置執行成本公式,精確地預測模型在不同異構裝置所需的計算成本,並使用動態規劃方法(dynamic programming)推導出最佳執行時間的排程方案。此外,我們設計了流水線排程方法(pipelining),在不同裝置上並行處理獨立的運算,達成平行度的最大化。以圖一的CNN+RNN視頻字幕模型為例,我們的細粒度排程方法將模型計算映射到最適合的計算裝置上,相比完全使用ARM處理器的執行方法,改進了DenseNet-LSTM效能達39倍。通過以流水線平行計算方法,更提升執行效能至55倍,達到每秒59幀的字幕推理速度。此運算速度是全球第一個在邊緣設備上執行DenseNet-LSTM大型模型,並達成實時(real-time)視頻字幕的執行效能。此研究成果發表於頂級會議IEEE IPDPS'21和頂級期刊ACM TACO 2022。
此外,我們將排程算法擴展至更複雜的深度學習模型,例如NASNet、ResNext和ensembles,其模型計算圖具有分支結構或是複雜的執行順序關係。因結構複雜性,使得此類模型很難找到良好的順序執行(sequential execution)排程。除此之外,現代硬體通常具有高運算力,順序執行運算子可能造成硬體資源的使用效率低落。針對此問題,研究團隊設計了運算子間(inter-operator)平行排程演算法,利用在獨立運算子間的平行處理,達到提高硬體資源使用率和縮短執行時間的雙重目標。然而過度的增加運算子間平行計算可能會超出處理器的資源限制,並造成執行效能下降。因此,我們為所提出的排程演算法加入了資源使用率感知(resource-utilization-aware)強化,以推導出最佳平行化的執行規劃。TVM是目前最好的AI編譯器,其採用順序執行方法依序處理複雜結構模型的運算子,和TVM相比,我們的平行排程方法可以使複雜模型在Nvidia RTX 3090 GPU上達到3.76倍的效能提升。此研究成果發表在ICPADS'22國際會議,並獲得了最佳論文獎亞軍。
資源利用率最佳化
由於高效能與低能耗的需求,過去幾年針對特定領域的加速器架構(domain-specific architecture)不斷被設計出來,例如用於加速深度學習推理的Google EdgeTPU加速器。深度學習加速器通常僅支援非常有限的運算子,例如基本的矩陣乘法或卷積運算。當深度學習模型中包含了不支援的操作時,其計算將交給輔助處理器(例如CPU)執行,這導致模型執行將在加速器與輔助處理器之間不斷切換,造成了加速器的資源使用率下降和的執行切換的額外負擔。為了解決這個問題,我們開發了一個基於MLIR編譯器的模型轉換軟體,此工具可以將模型中不支援的計算,利用支援的操作子轉換成相同功能的計算。除此此外,我們提出了一種通用的近似方法,針對無法轉換成相同功能的計算,可以利用ReLU這種廣泛支援的運算子,來近似任意連續函數並達到任意精準度。因此,任何支持ReLU的加速器都能受益於我們所提出的方法。圖2列出了利用兩個ReLU來近似softplus函數的範例。透過所提出的模型轉換技術,我們可以將許多不支援的模型完全執行在深度學習加速器上,達到加速器使用率的最大化。
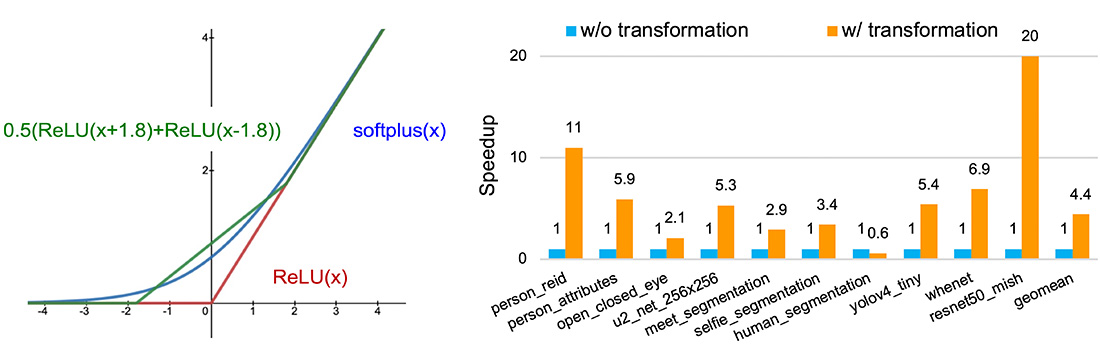
在ARM+EdgeTPU的邊緣平台上,相較於未經轉換的模型,我們的方法平均提高了模型性能達4.44倍。這項研究成果發表在ICPADS'22國際會議。
高效能壓縮模型執行
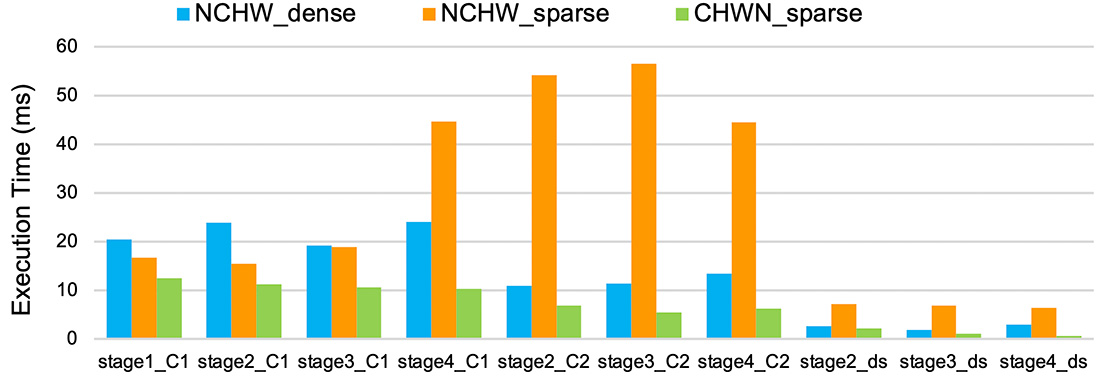
模型壓縮(例如剪枝、量化和知識蒸餾)是一種用來降低深度學習模型記憶體需求和計算複雜度的技術。這項技術對於在資源有限或計算能力低的嵌入式設備上部署模型尤其重要。要高效能執行壓縮模型通常需要特殊的硬體支援。然而,我們的研究團隊證明使用軟硬件協同優化方法,也能在常見的處理器(如CPU)上達到執行壓縮模型的效能提升。我們的壓縮模型優化編譯器以TVM為基底,設計了多種優化方法,包括張量記憶體配置轉換以提高快取局部性(locality)、利用向量化和屏蔽等CPU常見的指令功能,成功將最先進的模型壓縮技術(包括column-combining和fine-grained structured pruning)產出高性能的執行機器碼。以圖3中ResNet-18的卷積層為例,與未壓縮的模型相比,我們的編譯器優化方法能大幅降低壓縮模型中所有卷積層的執行時間(CHWN_sparse)。