計畫成員 : 馬偉雲、王新民
全球聊天機器人市場潛力市場相當龐大,但其中關鍵的痛點是:要開發一款夠聰明的聊天機器人,開發人員必須投注大量的時間精力來編寫腳本或是提供訓練資料。然而,要針對任何指定的特定商品類型蒐集大量對話的素材,無論是文字或語音,在實務上都相當困難。
基於此,從2023年開始,馬博士和王博士的研究團隊執行由中研院資訊所資助的所內合作計畫 (2023/1~2024/12),我們提出了一個大膽的想法,即 "Data To Chatbot",也就是說,不需要訓練資料或是編寫腳本,製作平台就可以針對商品設計出對話腳本甚至促銷策略,並且能透過語音跟使用者互動,整個過程完全“智慧製造”。
其中的關鍵在於針對特定產品,聊天的素材從何而來? 事實上,產品除了有型錄的資訊可供利用之外, 許多產品在網路上充滿了大量的使用心得文章。我們利用資料擷取技術以及文本摘要技術從中搜尋並擷取出合適的聊天素材,並轉化為口語化的表達方式。如此,以這些第一手的使用經驗作為聊天的素材,既能夠符合事實又具有說服力,可以做到有溫度又具備差異化的推薦。同時,我們也利用這些使用心得文章,作為口語語音理解的訓練材料。
整體架構圖如圖一,其中橘色框表示自然語言處理(Natural Language Processing, NLP)相關技術,綠色框表示口語處理(Spoken Language Processing, SLP)相關技術。紅色字體表示本計畫開發的新技術。使用者(User)的語音經自動語音辨識(Automatic Speech Recognition, ASR)模組,一方面轉換成完整文字,另一方面擷取關鍵詞。完整文字將經由自然語言理解(Natural Language Understanding, NLU) 模組進行意圖(Intent)分類以及關鍵詞擷取,兩種途徑產生的關鍵詞再加以統合,形成user輸入語音的語義框架(Semantic Frame)表示,再交由對話管理(Dialogue Management, DM) 模組來決定回應策略以及追蹤目前聊天狀態。策略的依據有兩種來源,一種是型錄,一種是使用者心得文。自然語言生成(Natural Language Generation, NLG) 模組再根據語義框架和回應策略生成機器人(Bot)要回應的文字,最後經由文字轉語音(Text to Speech, TTS) 模組生成語音訊號,回覆給使用者。
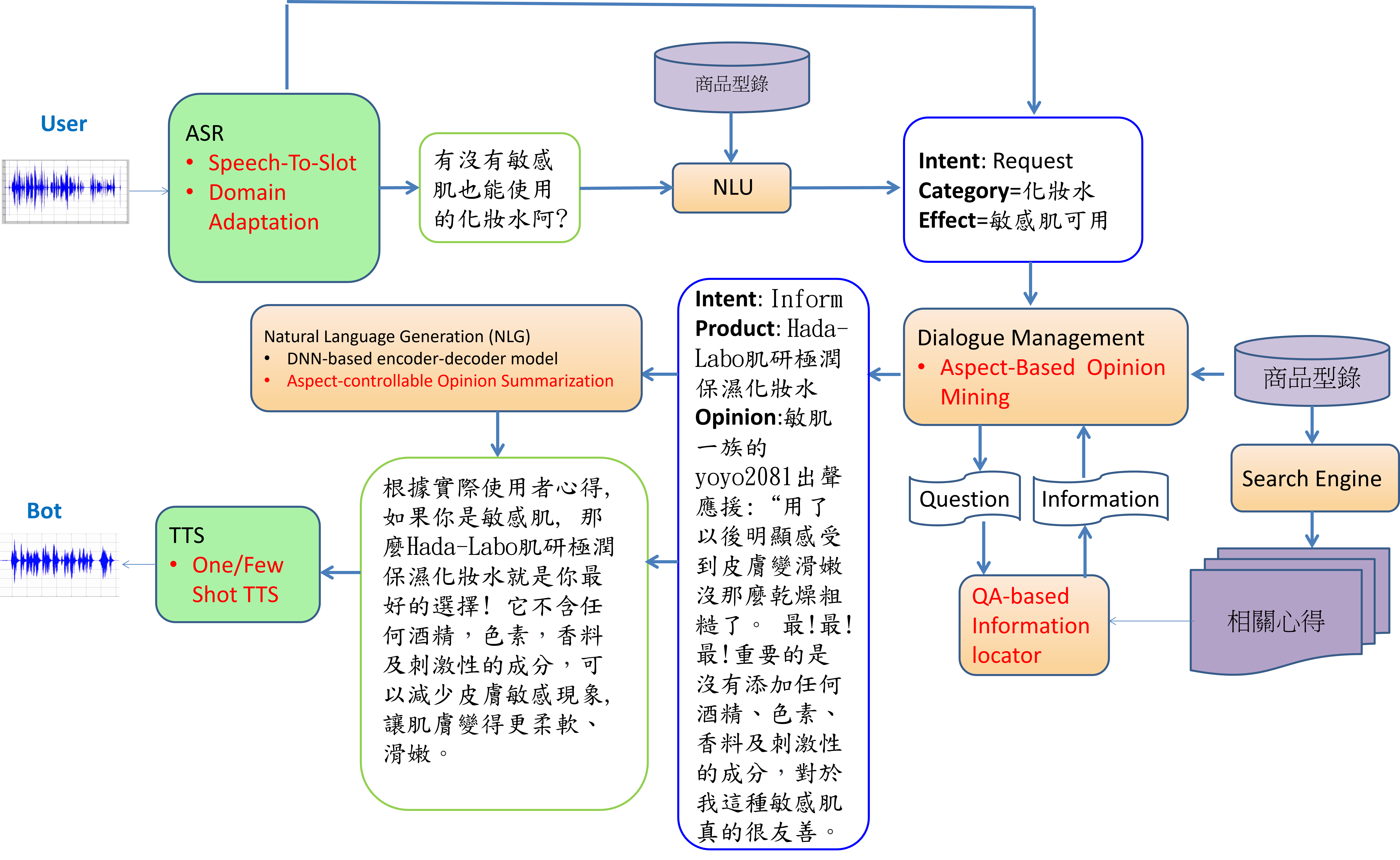
我們以資料擷取技術以及文本摘要技術從網路上的使用心得文當中擷取出合適的聊天素材。相關文字心得的資料通常非常龐大,其中的內容更是五花八門,即使都是關於特定商品的心得,大部分可能並不適合作為聊天素材,如何做到大海撈針,搜尋到合適的,有說服力的聊天素材,並從書面語改寫成口語,每個環節均充滿挑戰。我們的技術能針對任意指定的層面 (例如特定的產品功效)進行聊天素材的生成。我們過去曾經以餐廳評論中提到的不同“菜色”作為指定的層面而得到相當不錯的結果,在這個計畫中,我們會以美妝保養為主要領域,以產品的各項功效(例如“保濕”、“美白”等)作為指定的層面,來產生聊天的素材,並進一步開發一個模型評估生成的文字是否具有吸引力,並且加以量化,給予分數,而後再用這個吸引力分數結合強化式學習進一步優化文字生成,使得生成的文字能更具有吸引力。
在語音的理解方面,傳統的作法是流水線(pipeline)法,先透過ASR將輸入語音進行逐字辨識轉成文字,再經由NLU取出語義,分段的作法難免會有錯誤傳遞(error propagation)的問題。我們將以這個作法為基線模型,研究直接從語音中擷取語義的作法,也就是端到端(end-to-end)的口語理解(Spoken Language Understanding, SLU)技術,必要時可與流水線法加以統合,增加強健性。
在語音生成方面,除了提供一個通用的多語者TTS系統,可輸出指定語者的語音外,為了滿足可任意新增客服人員音色或語氣的要求,我們將開發One/Few Shot TTS技術。另外,由於ASR&SLU的模型訓練需要大量的具標記的領域內訓練語音,為每次的任務進行大量錄音的成本太高,我們將研究以多語者TTS和one-shot/few-shots TTS技術產生大量的ASR&SLU的訓練語音,也就是進行ASR&SLU的訓練語音的自動資料擴充(data augmentation)。