PIs: Li Su and Jen-Chun Lin
Current generative AI technology still faces significant technical hurdles in generating content that incorporates themes, storytelling, and integrates audiovisual information, such as in movies and character animation. Thus, such productions still rely heavily on manual labor and expensive techniques like human motion capture (MOCAP). In recent years, the rise of virtual musicians and VTubers has increased the demand for automatic content generation in movies and character animation. Therefore, starting in 2022, we began executing a theme project supported by the Academia Sinica, “Understanding and Generation of Audio-Visual Multimedia Content with Deep Learning” (2022/01 - 2024/12). In the year prior to the project’s execution, our research team prioritized two technical aspects: first, estimating the 3D pose and shape of characters from monocular video to reduce reliance on human motion capture technology; second, a virtual musician video generation system that uses music as a prompt and integrates four types of character animation information, including body movements, finger positions, facial expressions, and video shots.
Music-prompted virtual musician video generation system
Taking violin performance as an example, we handle four types of information related to virtual musicians’ playing in video: body movements, fingerings, facial expressions, and video shots, with the goal of generating performance videos that match the music. Our research team has been continuously collecting the dataset of music and body movements over the past few years. We have also developed models for generating 3D skeletal points of body movements and violin fingerings from music, as well as an automatic accompaniment system that supports human-machine duet. The results have been published in top conferences such as ACM Multimedia and ISMIR and have been used in public performances. Recently, we have further developed two new models: a facial expression generation model and a camera work model.
In the facial expression generation model, we map the music signal played by the violinist in the training data to their facial expression changes. We trained a 3D convolutional neural network (3D CNN), whose input is the music signal and output is the facial landmarks. Currently, it is known to be superior to other audio-to-facial-landmark generation models, and the results will be presented at IEEE ICASSP 2023. The facial landmarks and facial expression images generated in this stage can be used to generate virtual musician's facial model parameters. In the video shot generation model, we used the visual storytelling model developed by Dr. Jen-Chun Lin from our research team. To apply this model to classical music concert videos, we built a new concert camera position database for parameter adjustment. At this point, we have been able to integrate the virtual musician’s playing video generation system, which can automatically generate virtual musician’s playing videos by only inputting the music signal, as shown in Figure 1. The system has been verified in our lab's public live streaming video “The Online Music Salon for Engineers and Virtual Musicians”: https://www.youtube.com/watch?v=rVoDGc0dQ7g.

3D Human Pose and Shape Estimation from Monocular Video
In modern movies, games, and animations, computer-generated (CG) characters are primarily created using a MOCAP system. This wearable device is designed to capture the 3D pose and shape of a character. However, the cost of a professional optical MOCAP system is quite high, amounting to hundreds of thousands of dollars. Consequently, in this sub-project, our objective is to develop computer vision techniques for directly estimating the 3D pose and shape of characters from captured videos, which aims to reduce the production costs associated with CG characters in movies, games, and animations.
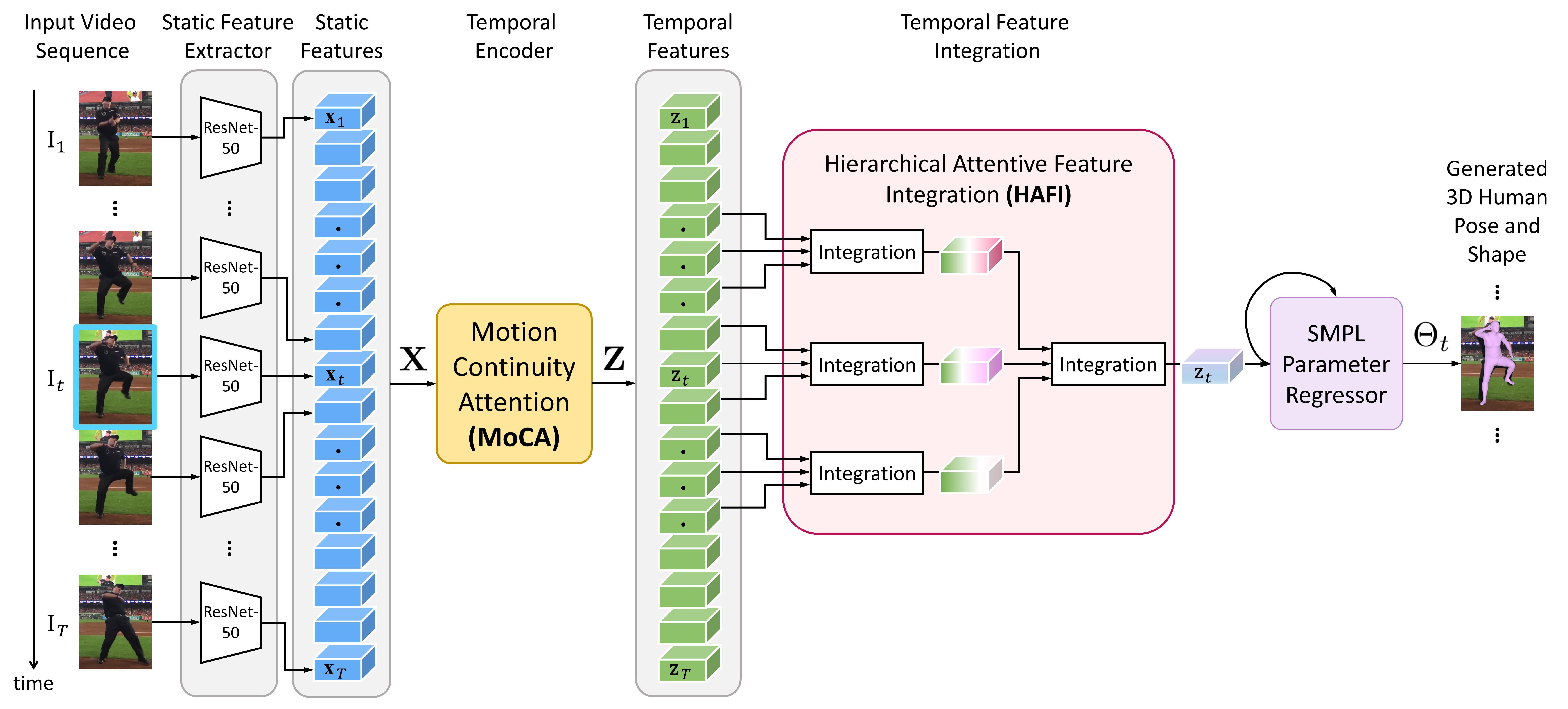
Current methods for video-based 3D pose and shape estimation primarily rely on recurrent neural networks (RNNs) or convolutional neural networks (CNNs) to capture temporal information in human motion. However, research has shown that RNNs and CNNs excel at modeling local (short-term) temporal dependencies but struggle to capture global (long-term) temporal dependencies in human motion. In addition, we have observed that improvements in estimation performance with existing methods primarily depend on utilizing larger neural network architectures, which in turn may limit the practical application of such techniques. To address these issues, we propose a motion pose and shape network (MPS-Net), as illustrated in Figure 2, which incorporates two novel attention mechanisms: the motion continuity attention (MoCA) module and the hierarchical attentive feature integration (HAFI) module. These mechanisms aim to model the global and local temporal dependencies more effectively in human motion. By substantially reducing the number of network parameters to approximately one-third of those in current state-of-the-art methods, our approach still improves the accuracy of 3D pose and shape estimation.
As can be seen from the experimental results in Figure 3, compared to the current state-of-the-art method, namely the temporally consistent mesh recovery (TCMR) system, the 3D pose and shape estimation provided by our MPS-Net can better fit the characters in the input images, particularly in the limbs.

Figure 4 further demonstrates the success of applying the 3D human motion estimated by MPS-Net to virtual characters, achieving 3D character animation control based on computer vision technique. For more results, please visit https://mps-net.github.io/MPS-Net/. Our work is published in CVPR 2022, and we are currently engaged in further developing this project.
