PIs: Tyng-Luh Liu and Hwann-Tzong Chen
Following our previous four-year AI research venture (2018/01—2021/12), this project (2021/11—Present) is a continuing effort towards developing emerging computer vision techniques and exploring their applications in smart manufacturing. In the previous AI project, we have made technical contributions on addressing the following topics: (1) natural language driven computer vision applications, including referring image segmentation and referring 3D instance segmentation; (2) zero-shot and few-shot visual classification, including proposing meta learning with mixup augmentations and establishing the framework of query-driven multiple instance learning (qMIL), which is applicable for handling both few-shot and zero-shot learning scenarios; (3) one-shot object detection, including proposing the coupling of co-attention and co-excitation as well as an adaptive image transformer model to achieve the detection task. All these encouraging accomplishments inspire our commitment to devote further endeavor into this collaborative research and particularly, set our goals in advancing computer vision techniques for the following five main topics.
- Image- and video-based anomaly detection: Aiming for developing core computer vision modules for smart manufacturing, we consider two application scenarios of anomaly detection. The first concerns image-based defect detection and localization whose objective is to uncover any anomalous defects in objects. We have developed a unified Metaformer model to achieve anomaly detection for not only instances of seen classes but those of unseen classes, with the help of few-shot meta tuning. The second scenario is about video anomaly detection. Specifically, we are interested in localizing unexpected actions or activities in video sequences. To simultaneously address both one-class and weakly-supervised formulations of this problem, we have proposed self-supervised sparse representation to yield a general framework that yields state-of-the-art performances. (See Figure 1.)
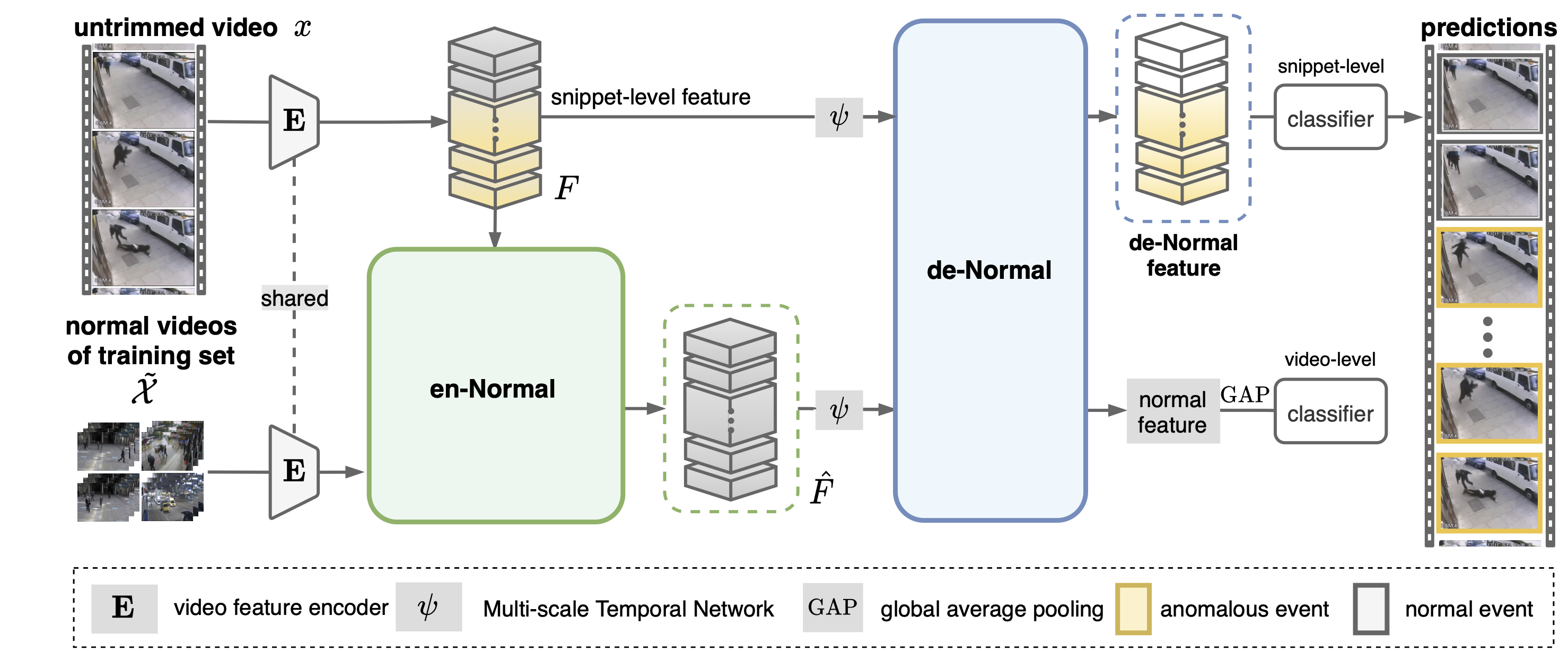
Figure 1: Self-supervised sparse representation (S3R) for video anomaly detection. - Visual classification under challenging scenarios: Image classification for real-world applications often involves complicated data distributions such as fine-grained and long-tailed. To jointly resolve the two challenging issues, we propose a new regularization technique that leads to an adversarial loss to strengthen the model learning. For each training batch, we construct an adaptive batch prediction (ABP) matrix and establish its corresponding adaptive batch confusion norm (ABC-Norm). (See Figure 2.) The ABP matrix is a composition of two parts, including an adaptive component to class-wise encode the imbalanced distribution, and the other component to batch-wise assess the softmax predictions. The ABC-Norm yields a norm-based regularization loss, which can be theoretically shown to be an upper bound for an objective function closely related to rank minimization. Our current research along this line now focuses on its generalization for incremental learning.

Figure 2: Overview of adaptive batch confusion norm (ABC-Norm). - Computer vision techniques for 3-D point clouds: Our primary goal is to develop 3-D computer vision techniques that have potential uses in smart manufacturing. These days the most popular 3-D data format is point clouds, which often comprise massive amounts of points, say, for an indoor scene. To facilitate its practical use in computer vision applications, we seek to establish a sampling strategy for point clouds so that the resulting reduction would be representative and gives rise to efficient implementation of an underlying deep learning model. In addition, our other research focal point is to design 3-D anomaly detection techniques for point clouds, and so far, the preliminary results are promising.
- Few-shot/language-driven action and interaction detection: Hinted by a modest support set, few-shot action detection (FSAD) aims at localizing the action instances of unseen classes within an untrimmed query video. Existing FSAD techniques mostly rely on generating a set of class-agnostic action proposals from the query video and then finding the most plausible ones by assessing their correlation to the support set. Such two-stage approaches are feasible but not efficient, largely due to neglecting the support information in generating the proposals. We look into the one-shot image scenario and introduce the attention zooming in strategy to effectively and progressively carry out support-query cross-attention while generating proposals. The resulting one-stage model yields high-quality action proposals for boosting one-shot action detection performance.
- Unsupervised representation learning: Contrastive learning (CL) is one of the most successful paradigms for self-supervised learning (SSL). In a principled way, it considers two augmented views of the same image as positive to be pulled closer, and all other images as negative to be pushed further apart. However, behind the impressive success of CL-based techniques, their formulation often relies on heavy-computation settings, including large sample batches, extensive training epochs, etc. We are thus motivated to tackle these issues and establish a simple, efficient, yet competitive baseline of contrastive learning. Specifically, we identify, from theoretical and empirical studies, a noticeable negative-positive-coupling (NPC) effect in the widely used InfoNCE loss, leading to unsuitable learning efficiency concerning the batch size. By removing the NPC effect, we propose decoupled contrastive learning loss, which removes the positive term from the denominator and significantly improves the learning efficiency. DCL achieves competitive performance with less sensitivity to sub-optimal hyperparameters, requiring neither large batches in SimCLR, momentum encoding in MoCo, nor large epochs.