PIs: Yu-Fang Chen and Yuan-Hao Chang
With the explosive growth of data, the conventional von Neumann architecture has difficulty on efficiently handling the excessive amount of data movement during the execution of machine learning algorithms and the deep neural network trained with big data in various applications. Motivated by the need to resolve the von Neumann bottleneck caused by the excessive amount of data movement, this collaborative project aims to study the memory-centric computing architectures and accelerators for next-generation machine learning, neural network, and quantum simulation/verification applications. The main theme of this project is on selecting an appropriate memory-centric approach for a target application and proposing optimizing strategies based on the characteristics of the application and underlying memory/storage computing hardware. The basic concept of memory-centric computing is to move part of the computational power from the processing unit (e.g., CPU, GPU, and FPGA) to the memory unit and even the storage unit. Thus, this project will focus on studying the memory-centric computing-based non-von Neumann structures, including processing-in-memory (PIM), processing-near-memory (PNM), and in-storage computing (ISC).
The preliminary results
In the line of memory-centric designs, we are the pioneers to tackle the scalability issue of ReRAM crossbars and to enable using NAND flash to support PIM. First, we tackle the scalability issue of ReRAM-based crossbar by resolving its analog variation error issue, because ReRAM-based crossbar performs multiply-accumulate (MAC) operations on the analog aspect by setting different input voltages and resistance values and determines the results through the output current. Based on such an observation, we proposed an adaptive data manipulation strategy to resolve the analog variation issue with a weigh-rounding design and an adaptive input sub-cycling design. This result has been published on top conference ACM/IEEE EMSOFT’20 and top journal IEEE TCAD in 2020.
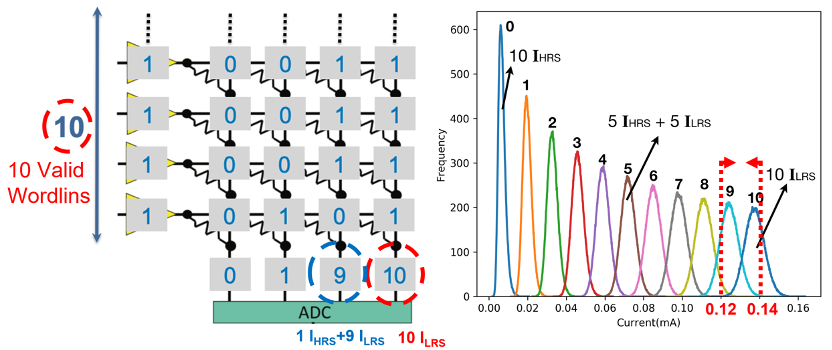
After resolving the scalability issue, we extend our study on the sparse graph issue when ReRAM crossbar arrays are used as the computational memory. We propose a graph-aware scheme that includes a systematic order preprocessing approach to better utilize the operation units on the ReRAM crossbar accelerator. Meanwhile, this scheme also has a local index compression approach that further refines the graph data compression to solve the local sparsity issue. The experiments show that the proposed scheme can improve the crossbar utilization by 31.4% and save energy by 17.2% on average. Our work on this direction has been accepted by top conferences ACM/IEEE ISLPED’21 and top journal ACM/IEEE ICCAD’22. In addition, we also enable the ReRAM crossbar to support the inference of random forest with the performance enhancement for up to 3.13 times; this research is accepted by top conference ACM/IEEE DAC’23.
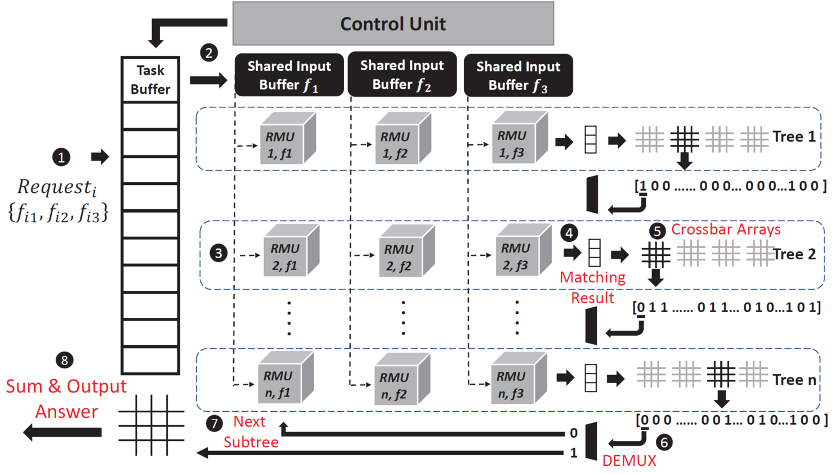
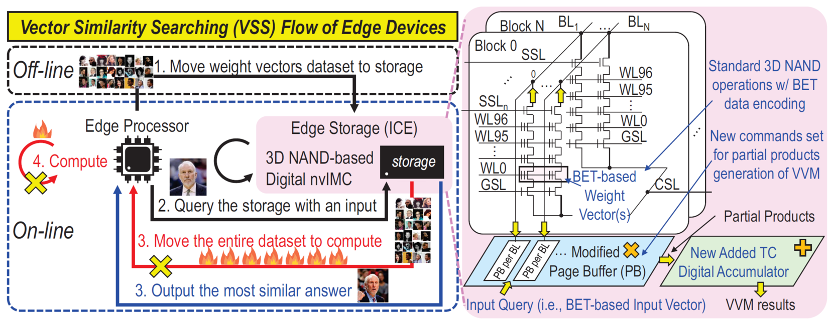
Furthermore, we also extend our attention to the vector similarity search (VSS) for unstructured vectors generated via machine learning methods, where VSS is a promising solution for many applications, e.g., face search. In order to avoid the excessive amount of data movement from NAND storage and DRAM for the VSS, we developed an intelligent cognition engine (ICE), a 3D NAND-based in-memory computing design, to accelerate the processing of VSS. In the proposed ICE design, we develop an ADC/DAC-free digital-based in-memory-computing technique featuring high density; meanwhile, we also propose a bit-error-tolerance (BET) data encoding to mitigate the reliability issue and facilitate parallel vector-vector-multiplication (VVM), so as to accelerate the VSS computation. The experiment results show that our ICE design can enhance the system performance by 17x to 95x and energy efficiency by 11x to 140x. This work has been accepted by the top conference ACM/IEEE MICRO 2022, which is one of the three best conferences in the field of computer architecture. Only very few researchers in Taiwan have published papers in this conference in the past several decades. In addition, we also develop an In-Memory-Computing 3D-NAND flash to support similar-vector-matching (SVM) operations on edge-AI devices, and this work has been published on the top conference IEEE ISSCC’22.
Future Directions
In the future, we will keep studying the memory-centric computing architectures for next-generation quantum simulation/verification, machine learning algorithms, and neural network accelerators. In particular, we will tackle the critical issues of selecting and designing (1) appropriate memory-centric computing architectures, (2) emerging non-volatile memory technologies (e.g., ReRAM, PCM, MRAM, and flash memory) that support in-memory (or in-storage) computation, (3) optimizing strategies based on the characteristics of the target application and hardware design, and (4) efficient and effective simulation platform to estimate the efficiency of the proposed architecture. The major research tasks/objectives will include (1) exploiting the processing-in-memory architecture for applications, (2) adopting the processing-near-memory architecture for big-data applications, and (3) in-storage computing design and optimization.