研究人員
研究群介紹
在資料爆炸的時代裡,各種資料,例如感應器資料、軌跡資料、交易資料、多媒體資料,以飛快的速度時時刻刻產生。目前硬體與網路高質與量,價錢相對便宜,是最佳時刻來發展相關研究議題,來善用這些資料來來改進現有服務,或用來解決目前無法解決的問題。所以本研究小組的主要目標在於起始相關創新研究以達科學與技術的卓越性。目前我們著重於以下研究領域 (1) 有效收集、表現、儲存、與處理大量各式資料,(2) 探討資料探勘技術來有效率、有效益來發現有價值的知識。目前我們研究的議題包括 (1) 社群網路分析與查詢處理,(2) 機器學習於網路廣告即時競價,(3) 深度學習於都會區空汙預測,(4) 非揮發性主記憶體之索引設計與資料探勘。各計畫簡述於下:(1) 社群網路分析與查詢處理
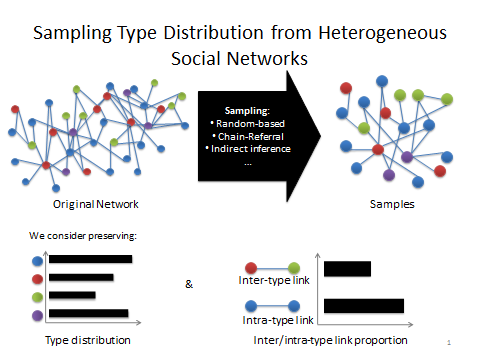
社群網路方面的研究貢獻集中於高效率的社群群體查詢以及社群影響力。關於地理位置社群網路(Location-basedSocial Networks),我們提出了新的索引結構並提出社群空間群體查詢(Social-Spatial Group Query),以快速找出距離近且社群關係緊密之社交群體,並求得適當位置給予所得之群體。除了考慮時間及空間外,我們亦考慮使用者之偏好群體搜尋,並設計具效能保證之隨機演算法,其可運用於線上至線下的社群應用或是團購優惠服務。對於職業社群網路,我們提出了新的社群空間查詢,為了形成專業工作團隊,在進行查詢時考慮到群組距離、群組成員的專業技能以及群組中社群關係。我們證明了此問題在任意比例內的不可近似性,但在允許可接受誤差的狀況下,我們設計了一個保證錯誤誤差之近似演算法。此外,考慮到社群心理學中的社會臨場感理論(Social Presence Theory),我們提出一個新的有效認識新人群之社群群體查詢問題,並設計了一個3 倍近似演算法。
此外,針對特定對象的影響力傳播,我們提出一個新的最佳中介節點選擇問題,以改變特定對象之決定,而我們也提出行動社群網路中的分散式作法。我們亦結合了頻繁樣式探勘(Frequent Pattern Mining),提出與多個相關商品組合銷售之病毒式行銷影響力傳播最佳化問題。我們提出以超圖(Hypergraph) 與超邊(Hyperedges) 為基礎以頻繁樣式之社群物件圖(Social Item Graph),提出了一個近似演算法,並基於FP-Tree 設計了一個新索引結構。另一方面,我們觀察到資料探勘線上社群行為,可有效達成早期自動辨認社群網路心理疾病(Social Network Mental Disorder,SNMD) 之目的。我們提出了一個機器學習作法-社群網路心理疾病偵測(Social Network Mental Disorder Detection,SNMDD) 以及基於社群網路心理疾病的張量模型(TensorModel),以精確地偵測出可能發生社群網路心理疾病的情況,且其實驗結果表明了社群網路心理疾病偵測對於辨認出可能患有社群網路心理疾病的使用者相當有效。關於群體治療,我們提出一個線上互助群體成員 (Member Selection for Online Support Group,MSSG) 選擇問題,在確保群體中任意兩位成員間並不熟識的狀況下,將所有成員的症狀的相似度最大化。我們證明MSSG 是個NP-Hard的問題,且在任意比例內不可近似,故設計了可保證誤差之3 倍近似演算法。
(2) 機器學習於網路廣告即時競價
網路展示型廣告已由過去固定內容固定價位的銷售方式,演變成為現在根據不同瀏覽人次由競價結果動態決定內容:在使用者造訪網址且網頁完整呈現的短時間內,有興趣的廣告主們透過程式化交易競標爭取廣告曝光。在即時競價交易環境中,廣告主要能快速且精準地跨媒體購買廣告,必需仰賴好的預測模型自動出價。本實驗室目標協助廣告主在有限且不完整的歷史競價資料中,設計出合適的機器學習方法,以建立有效的預測模型來精準地預測廣告點擊率,進而能在有限的廣告成本下決定適切的出價策略。
(3) 深度學習於都會區空汙預測
都會區空氣汙染預測與汙染源偵測是一個待解的急迫問題,嚴重影響到環境、健康、經濟,以及公共利益。近三年來已有很多研究使用各種方法,包括類神經網路、機器學習方法、圖形理論、統計學、氣象模式,或以上的組合,來做細密度的空汙推估或是預測。但是大部分研究都無法精確預估都會區空汙情形,因為除了遠端輸送汙染物外,都會區本身是空汙製造者。在本研究我們提出一個使用多種類神經網路( 包括autoencoders,LoEs,LSTMs,RBNs) 的深度學習架構來描述影響都會區空汙的因素與特性。目前我們更進一步結合氣象模式來造模外來空汙,更準確的提供都會空屋模式。
(4) 非揮發性主記憶體之索引設計與資料探勘
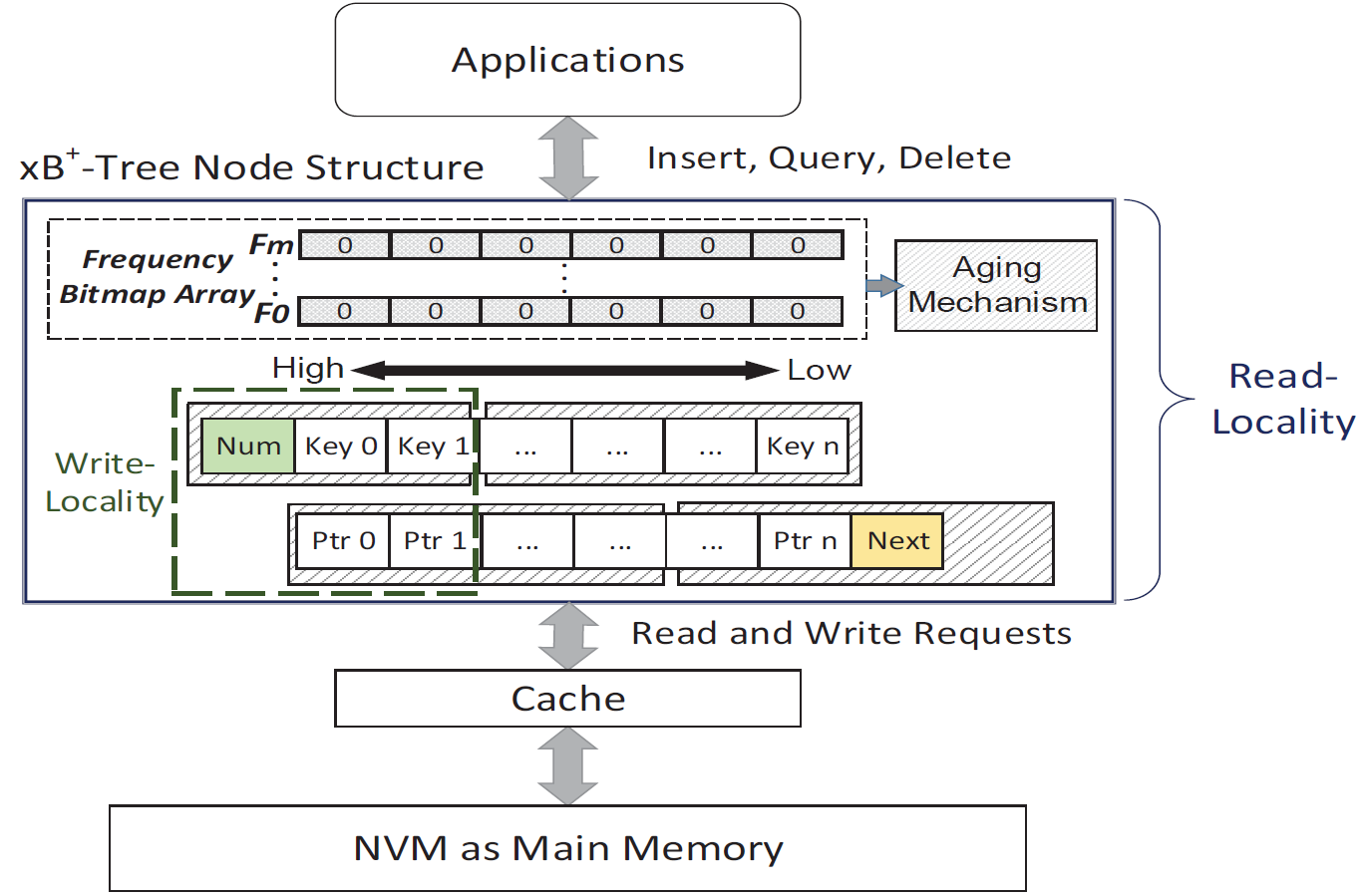
非揮發性記憶體被廣泛的使用在次世代記憶體架構的發展之中,同時也成為一個取代 DRAM 成為特殊應用系統之主記憶體的重要媒體。除了非揮發性之外,非揮發性記憶體同時具有低漏電與高容量可擴增性的優點。然而與DRAM 相比,非揮發性記憶體通常具有較長的寫入延遲與寫入耗電。我們的研究著重在考慮物聯網及記憶體資料庫等特殊資料存取行為的應用之下,提出新的設計來提升非揮發性主記憶體架構的資料存取效能。例如,我們提出名為存取行為感知樹 (xB+-tree) 的新索引設計來提升非揮發性主記憶體架構的資料存取效能,此一設計考慮CPU 以快取列為主記憶體存取單位的方式來偵測主記憶體資料的存取行為,此一設計的主要概念為將經常存取的索引資料集中在最少的快取列空間之中,並把最近將會連續存取的資料也集中在一起,因此必須被讀取到CPU 快取列資料就能被最小化,此一設計經過Gem5 模擬器的一連串實驗,證明此設計具有極佳的性能。未來,我們將繼續研究非揮發性記主憶體在大數據應用與主記憶體系統上的索引設計。例如,大數據應用中,資料常常會大量的被收集但是極少被刪除,同時只有少部分的資料會被經常讀取或查詢,因此這裡的技術問題為如何從本質上提升快取列的命中率並降低快取未中機率。此外,非揮發性記憶體的壽命問題也會是我們未來的研究重點。
巨量資料時代來臨,隨機存取記憶體的容量已不足以負荷各種巨量資料探勘應用之記憶體內運算;而仰賴外部儲存媒體如硬碟之外部演算法更需可觀的資料搬移時間花費。現今非揮發性記憶體技術進步,可以較低的價位提供更高儲存容量,並具有不俗的資料讀取速度,因此成為很好的取代方案,讓巨量資料應用之記憶體內運算得以實現。然而,非揮發性記憶體寫入的速度顯著高於讀取速度,再加入上非揮發性記憶體有寫入次數的壽命限制。因此,本實驗室目標重新設計資料探勘演算法如頻繁樣式探勘等演算法,多以讀取的動作取代寫入的動作,使其能友善地利用非揮發性記憶體優點,在實現巨量資料探勘之效能同時,也能延長其使用壽命。